On February 6, 2025, Cloudflare experienced a major outage that rendered its R2 object storage service completely inaccessible for nearly an hour. The disruption, caused by an attempt to remediate a phishing report, had a cascading impact on multiple Cloudflare services.
What Happened?
Cloudflare R2, a scalable object storage solution similar to Amazon S3, suffered a complete outage when an employee mistakenly disabled the entire R2 Gateway service instead of blocking a specific endpoint associated with a phishing report. This mistake was attributed to both human error and insufficient safeguards within Cloudflare’s abuse remediation system.
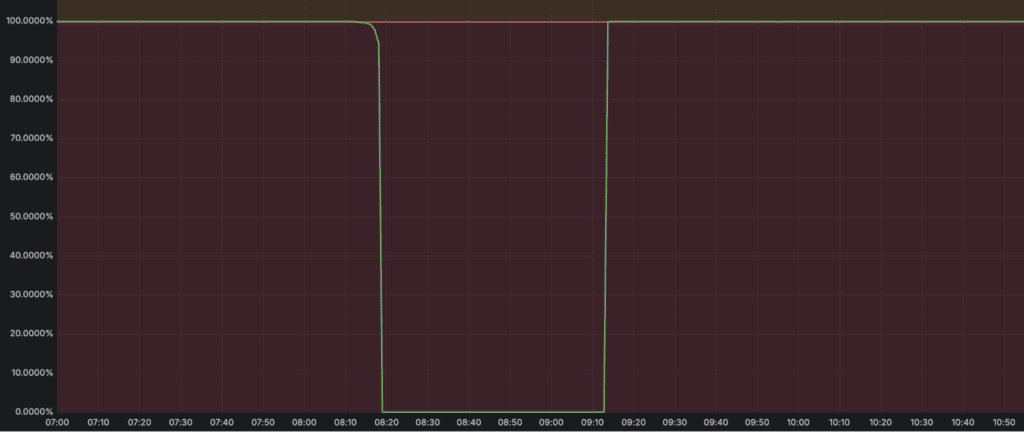
According to Cloudflare’s post-mortem, this incident was a failure of multiple system-level controls and operator training. The outage lasted from 08:14 UTC to 09:13 UTC, during which all operations against R2 failed, including uploads, downloads, and metadata requests.
Services Affected
Several Cloudflare services reliant on R2 were severely impacted, including:
- Stream: 100% failure in video uploads and streaming delivery.
- Images: 100% failure in uploads and downloads.
- Cache Reserve: 100% failure in operations, causing increased origin requests.
- Vectorize: 75% failure in queries, 100% failure in insert, upsert, and delete operations.
- Log Delivery: Up to 13.6% data loss for R2-related logs, up to 4.5% data loss for non-R2 delivery jobs.
- Key Transparency Auditor: 100% failure in signature publishing and read operations.
Additional indirect impacts included increased error rates for Durable Objects, Cache Purge, and Workers & Pages, though these remained relatively minor.
Cloudflare’s Response and Fixes
Cloudflare took immediate action to restore services and prevent similar incidents in the future. Key fixes include:
- Removing the ability to disable entire systems via the abuse review interface.
- Restricting Admin API capabilities to prevent internal service disablement.
- Implementing stricter access controls and validation checks for high-impact actions.
- Introducing a two-party approval process for system-level disablement actions.
Lessons Learned
This outage underscores the risks associated with human error and the importance of implementing strong safeguards against accidental service disruptions. While no data was lost from R2, the incident highlights the need for continuous improvements in automation, validation, and administrative oversight.
Cloudflare has committed to strengthening its operational controls and ensuring that future abuse remediation actions do not compromise system availability. As cloud services become increasingly critical to global infrastructure, such lessons are invaluable for the industry as a whole.
Source: https://blog.cloudflare.com/cloudflare-incident-on-february-6-2025/

Founder of ToolsLib, Designer, Web and Cybersecurity Expert.
Passionate about software development and crafting elegant, user-friendly designs.
Stay Updated with ToolsLib! 🚀
Join our community to receive the latest cybersecurity tips, software updates, and exclusive insights straight to your inbox!